Enrichment View¶
Databases can be enriched by encoding various elements. Usually, the database starts off with just words and phones, but by adding enrichments a diverse range of information will become available to the user for searching with the Query View later. All enrichments are added in the Enrichment View. Here are some details about this View and the Enrichment options available to the user.
Actions¶
Once an enrichment has been saved, a number of possible actions will become available for it. The actions buttons are available as a column in the table visible at the top of the Enrichment View
- Run If the enrichment is runnable, the user may run it to apply this enrichment to the corpus
- Reset The user may reset an enrichment to remove changes added to the corpus by running that enrichment. The state of the database will be as it was before running this enrichment
- Edit The user may make changes to the saved enrichment. For the changes to be applied to the corpus, hit Run again after editing
- Delete This has the same effect as Reset but also removes this enrichment from the Enrichment View. To re-run a deleted enrichment, the user must start over and create a new enrichment
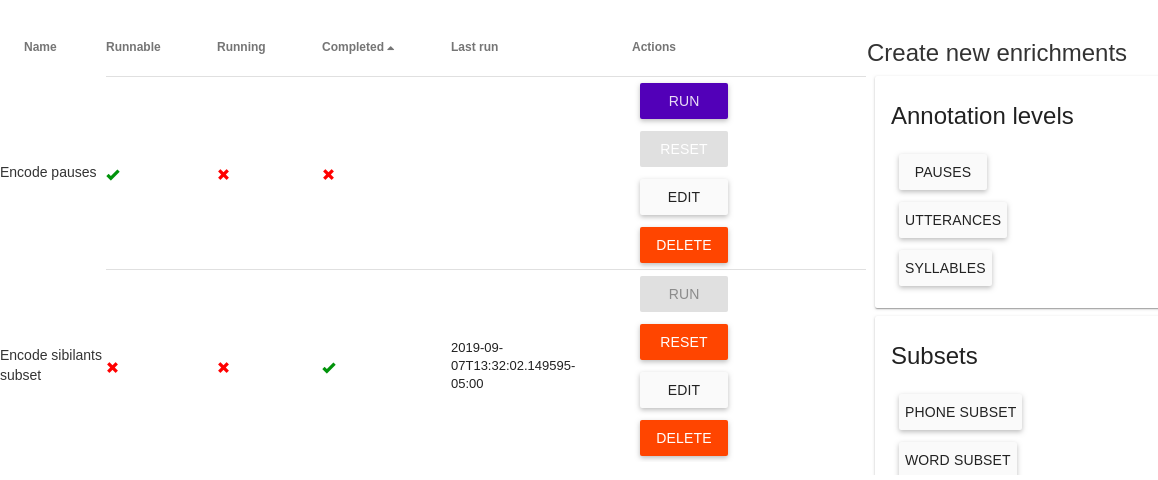
Create New Enrichments¶
To the right of the table of saved enrichments and actions are several options for enriching a corpus.
Annotation levels¶
- Pauses This allows the user to specify for a given database what segments should count as pauses instead of speech. These are typically among the most common words in a corpus, so top 25 words are provided (25 word default may be changed). If not found, custom pause labels may also be entered in the search bar.
- Utterances Define utterances here as segments of speech separated by a gap of a specified length (typically between .15-.5 seconds).
- Syllables If the user has encoded syllabic segments, syllables can now be encoded using a syllabification algorithm (e.g. maximum attested onset).
Subsets¶
- Phone subset Here the user may encode a subset of phones, such as vowels, stops, or sibilants, by selecting from the table which phone labels to include. All phones belonging to this subset will be labeled as such in the corpus. For some corpora, predefined subsets ‘sibilants’, ‘syllabics’ and/or ‘stressed vowels’ may be selected automatically.
- Word subset The user may choose to group a subset of words together by selecting from the list of all words appearing in the corpus.
Annotation properties¶
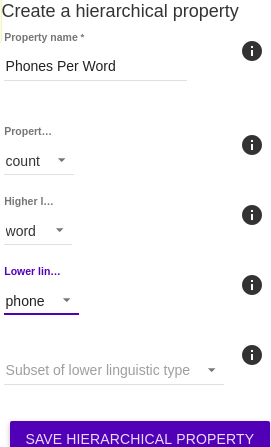
Hierarchical property This selection allows the user to encode properties involving two levels, such as number of syllables in each utterance, or rate of syllables per second.
- Property type Target property can be rate, count, or position. Rate will encode on the higher linguistic type number of lower linguistic type units per second (i.e., speech rate on utterances could be the rate of syllables per second). Count will encode on the higher linguistic type the number of lower linguistic type units that it contains. Position will encode on the lower linguistic type its position within the higher linguistic unit (i.e., position of syllables within a word).
- Higher linguistic type Upper level property in hierarchy
- Lower linguistic type Lower level property in hierarchy
- Subset of lower linguistic type The user may specify a subset of the lower linguistic type to use. If specified, units outside of this subset are ignored. For instance, speech rate for a utterance could be calculated as the rate of “syllabic” phones per second, rather than needing syllables encoded. Another example would be if certain words are of interest in an experiment, that subset can be specified for the position of words of interest within each utterance.
Example: To encode the number of phones per word, set Property type to count, Higher linguistic type to word, and Lower linguistic type to phones. You may leave the subset of a lower linguistic type blank, but the other fields must be filled as hierarchical properties involve some relation between two linguistic types.
- Stress from word property Enriches syllables with stress information (‘stressed’ or ‘unstressed’, coded as ‘1’ or ‘0’) via a listing for each word in the lexical enrichment CSV. The user must choose which property to use for encoding syllable stress. The property should have syllable stress separated by dashes (i.e., “1-0” for “dashes”). If there is a mismatch in the number of syllables in this property and in the database, the word’s syllables will not have any stress encoded.
- Properties from a CSV Here the user can import information to the corpus using CSV files saved locally
- Lexicon CSV Allows the user to assign certain properties to specific words using a CSV file. For example the user might want to encode word frequency. This can be done by having words in one column and corresponding frequencies in the other column of a column-delimited text file.
- Speaker CSV Allows the user to enrich speakers with information by adding speaker metadata, such as sex and age, from a CSV.
- Phone CSV Allows the user to add certain helpful features to phonological properties. For example, adding ‘fricative’ to ‘manner_of_articulation’ for some phones.
- Sound File CSV Sound file properties may include notes about noise, recording environment, etc.
- Custom properties from a query-generated CSV This option allows users to perform analyses outside of ISCAN, and then bring them in. For detailed information on how to use this enrichment, see Tutorial 4 in ISCAN Tutorials.
- Relativize a property This permits the user to encode certain statistics
- Linguistic type Specifies which linguistic type (for example, phone or word) will be relativized.
- Property Specifies which property of the linguistic type to relativize.
The user may also decide whether relativization should be performed within speaker (using by-speaker means and standard deviations). If this option is not selected, means and standard deviations will be calculated across the the whole corpus.
Acoustics¶
- Pitch tracks Here you can specify the program to use to generate pitch tracks (for example, PRAAT)
- Voice onset time Here a user may enrich the corpus with AutoVOT
- Stop subset This menu presents options for the subset of phones that will have their VOTs calculated
- Use custom classifier If this option is selected, you may choose your own classifier (The file format for classifier is a zip file containing both the pos and neg files from an AutoVOT trained classifier). Otherwise it will default to a classifier trained on voiceless word-initial VOTs in SOTC
- VOT Min/Max(ms) These values represent the minimum and maximum values of the VOT calculated. A minimum value of 15 ms will ensure that the difference between the closure and onset of voicing will be at least 15 ms.
- Window Min/Max(ms)
- Overwrite manually edited VOTs? Select this option to overwrite any VOTs that were manually edited in the inspection view
For convenience, default settings for voiced and voiceless stops are available
Formant tracks Here you can specify the program to use to generate formant tracks (for example, PRAAT)
Intensity tracks Here you can specify the program to use to generate intensity tracks (for example, PRAAT)
Refined formant points or tracks This option is for generating and refining formant point measures. The user must specify:
- The subset of phones representing segments over which the formant analysis will be run.
- The number of refinement iterations. Increasing the amount of iterations will significantly increase the amount of time it takes to run the analysis, but it may improve convergence and accuracy of measurements.
And the user may optionally specify:
- The minimum duration of a phone for it to be analyzed.
- A CSV file containing formant measure prototypes to seed the algorithm before the first refinement iteration. If no CSV file is selected, the prototypes are generated from the data.
- If you prefer to save tracks rather than a single point.
Custom Praat script This options allows you to run a custom Praat script over a specified type of annotation, or some subset of a type of annotation.
Relativize an acoustic track For this enrichment, acoustic tracks must already have been encoded. If multiple have been encoded, you may select which acoustic track will be relativized. You may also specify whether relativization should be performed within speaker (using by-speaker means and standard deviations). If this option is not selected, means and standard deviations will be calculated across the the whole corpus.